


The issue of AI web crawlers forcibly scraping website data has flared up again. It’s like an old argument that’s suddenly back in the spotlight, and this time it’s getting even more heated. People who create content online are frustrated, feeling like their work is being grabbed without permission. At the center of the latest drama is Perplexity. They’ve been accused of some sneaky tactics to get around website blocks, and it’s stirring up a bigger conversation about how AI companies handle data.
Cloudflare, which helps keep the internet running smoothly for a lot of sites, just put out a report that calls out Perplexity for what they describe as stealth crawling. Basically, their bots are ignoring the usual rules and finding ways to slip through. When a site tries to block them, these bots switch up their disguise, pretending to be regular browsers like Chrome on a Mac, and they rotate IP addresses to avoid detection. This isn’t happening on just a few sites. Cloudflare saw it across thousands of domains, with millions of requests hitting every day.
To figure out what Perplexity was doing, Cloudflare set up new websites with specific rules to block Perplexity’s AI scrapers. They watched to see how Perplexity’s bots would try to access these sites. At first, the bots would identify themselves as ‘PerplexityBot.’ But if they were blocked, Cloudflare noticed that the bots would then change their digital disguise, pretending to be a regular web browser and using different, unlisted internet addresses to get around the blocks. This showed Cloudflare that Perplexity was actively trying to hide its identity to access content it was told not to.
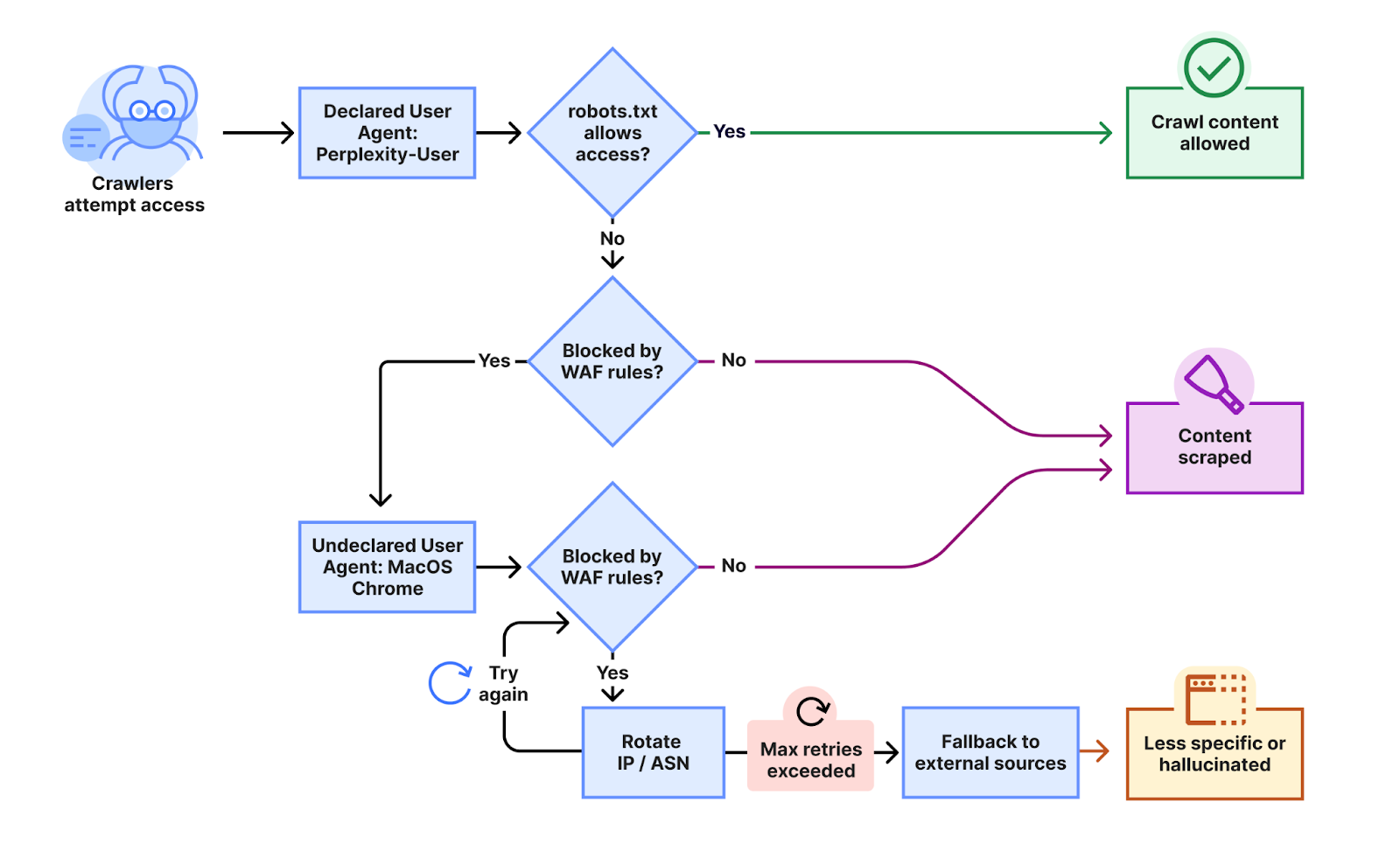
Perplexity pushed back, calling the report a publicity stunt and saying there were some misunderstandings in a statement to The Verge. But it’s hard to ignore the details in that report, especially when it points to a pattern.
This kind of thing has come up before with Perplexity. Last year, they got heat for ignoring robots.txt files, those simple instructions websites use to say stay out of certain areas. There were even claims they bypassed paywalls to grab premium content. Their CEO, Aravind Srinivas, blamed it on third-party crawlers back then.
Now, though, the new accusations suggest something more intentional, like a well-planned effort to dodge restrictions. Publishers see it as straight-up theft. Perplexity calls itself an answer engine that just aggregates info, but others argue it’s scraping without asking, which hurts the people who make the content in the first place. Without that original work, what would these AI tools even build on?
This situation feels oddly familiar to me since I recently also highlighted how Google AI Overviews are practically starving publishers of views while at the same time misinforming users.
Perplexity isn’t the only one in the crosshairs. Big names like OpenAI have dealt with similar complaints. Their GPTBot got called out for blowing past robots.txt rules, raising worries about copyright and even making some compare it to denial-of-service attacks that overwhelm sites. Lawsuits are piling up as publishers fight back, demanding that their intellectual property isn’t used to train AI without some kind of deal or payment. It’s a clash that’s been building, especially as AI grows so fast and needs massive amounts of data to learn.
For context, robots.txt has been around for decades as a polite way for sites to guide crawlers, mostly for search engines like Google. It’s not a law, just a handshake agreement. But AI crawlers are hungrier and more aggressive, and many are treating it like it’s optional. Website owners feel stuck. They want search engines to index their stuff for traffic, but they don’t want AI firms using it freely to build competing products. A few months ago, we highlighted how publishers can’t even opt out of AI Overviews without sacrificing Search. So essentially, they’re blackmailed into feeding Big Tech’s AI models with more data.
People are starting to fight back with fresh ideas. The Internet Engineering Task Force is working on something new through their AI Preferences group. They’re aiming for a better system where publishers can clearly state how their content can be used, maybe with a standardized tag attached to pages. It’s called llms.txt in some proposals, like an update to the old robots file but tailored for AI. Cloudflare’s getting creative too, with this AI labyrinth setup. They create fake webpages full of AI-generated junk to trap bad bots. If those bots scrape it and train on it, it could mess up their models, leading to what’s called model collapse. It’s a clever deterrent, like setting a trap in your yard for intruders.
Still, not everyone’s convinced these fixes will stick. If companies are already ignoring the basics, a new standard might not change much without real consequences, like laws or fines. As AI keeps advancing, this tension shows how the web’s openness can clash with business needs. Finding a balance won’t be easy, but it’s crucial for everyone involved, from creators to users who benefit from better search tools. We can’t let AI bots knock us humans off the map by scraping content with no permission.
TechIssuesToday primarily focuses on publishing 'breaking' or 'exclusive' tech news. This means, we are usually the first news website on the whole Internet to highlight the topics we cover daily. So far, our stories have been picked up by many mainstream technology publications like The Verge, Macrumors, Forbes, etc. To know more, head here.













Dwayne Cubbins
1421 Posts
For nearly a decade, I've been deciphering the complexities of the tech world, with a particular passion for helping users navigate the ever-changing tech landscape. From crafting in-depth guides that unlock your phone's hidden potential to uncovering and explaining the latest bugs and glitches, I make sure you get the most out of your devices. And yes, you might occasionally find me ranting about some truly frustrating tech mishaps.

