

Update 25/06/24 4:46 pm (IST): Meta has announced a setback in its plans to train large language models (LLMs) using public content from adult users on its platforms in Europe. The Irish Data Protection Commission (DPC), acting on behalf of European Data Protection Authorities, has requested a delay in this training process. Meta expressed disappointment with this decision, viewing it as a step backward for European innovation and AI development. The company maintains that its approach complies with European laws and regulations, and emphasizes its commitment to transparency in AI training.
As a result of this delay, Meta is unable to launch its Meta AI service in Europe for the time being. The company argues that without including local information, European users would only receive a “second-rate experience” compared to the rest of the world. Meta plans to continue working with the DPC to address concerns and ensure that people in Europe can access the same level of AI innovation as other regions. Additionally, the delay will allow Meta to address specific requests from the UK’s Information Commissioner’s Office before initiating the training process.
Original article published on June 3, 2024 follows:
Meta, the company behind Facebook, Instagram, and WhatsApp, has been developing artificial intelligence models to power features across its platforms. However, the tech giant recently revealed that it plans to use users’ data to train these AI systems by default, unless users explicitly opt out. If you’re concerned about your personal information being used for this purpose, Meta has provided a way to object—but the process is unnecessarily complicated. Moreover, it isn’t immediately clear if the option to stop Meta from using your data to train its AI models is available to users globally.
After reading articles, official documentation and user reports, I noticed that users in the EU are most likely able to opt out from Meta’s shenanigans. That said, I’ve put together detailed steps to opt out from the process, thanks to X user Tantacrul, who highlighted the process in detail.
The notification

In the past few days, Meta has been sending out notifications to users about “new AI features.” The notification reads: “We’re planning new AI features for you. Learn how we use your information.” This vague messaging doesn’t explicitly mention that Meta intends to use your data to train its AI models. It’s just the first step in an intentionally convoluted process designed to minimize the number of users who actually opt out.
The policy update
If you click on the notification, you’ll see a “Policy Update Notice” explaining that Meta will now use a legal basis called “legitimate interests” to train AI models with your data. This could include posts, photos, captions, and more that you share on Meta’s platforms. The notice states that you have “the right to object” to this use of your information, with a hyperlink to do so.
However, this “right to object” link is buried in the second paragraph and formatted as small, easy-to-miss hyperlinked text rather than a prominent button or call-to-action. The notice also includes a large “Close” button at the bottom, perhaps encouraging users to simply dismiss the update without understanding the implications.
Moreover, Meta includes an ominous line stating: “If your objection is honored, it will be applied going forward.” This implies that the company reserves the right not to honor your objection—a concerning prospect given the lack of clear legal safeguards around AI training with personal data.
The objection form
If you manage to find and click the “right to object” hyperlink, you’ll be taken to a form where you can officially object to having your data used for AI training. Here, Meta finally discloses the specific types of your content that may be used, such as posts, photos, comments, and more.
The form requires you to select your country and provide an email address. It also includes a text box where you must explain why you’re objecting to Meta using your data for AI purposes. Some users have had success citing data privacy laws like the GDPR in their explanation.
For example, one user-shared template states: “The use of my data infringes on my rights as a [your nationality/EU citizen] resident and EU citizen. I do not consent to my data being used for AI training, development, improvement, or a more personalized experience. I do not give consent for my data to be used for any other form of training, development, improvement, or a more personalized experience in any Meta product or technology. I have the right to keep my data private as per the European GDPR law.”
Adding insult to injury, the objection form includes a note saying Meta “may not be able act on your request” even after you’ve provided an explanation—leaving users’ objections in potential limbo.
The confirmation code
After submitting the objection form, Meta will send a one-time confirmation code to the email address you provided. You must enter this code, which expires after an hour, back into the form to complete your objection.
This extra step seems designed solely to add friction and discourage users from following through on their objection. As one Twitter user who has worked on streamlining user experiences pointed out, “Every additional step you add dramatically decreases the percentage of people who’ll make it through to the end.”
The (potential) confirmation
If you successfully complete all of the above steps, you may receive a confirmation email stating that Meta will honor your objection and not use your data for AI training purposes. However, some users have reported receiving error messages instead, even after properly following the process.
This inconsistency and lack of clarity from Meta underscores how difficult the company has made it for users to opt out of a major new data collection and usage policy. By burying important information, adding unnecessary friction, and leaving room for objections to potentially be ignored, Meta seems to be actively discouraging users from retaining control over how their personal data is used.
What if you don’t get the notification?
If you haven’t received the notification, then don’t fret! If you are in a supported country, you can visit this link to fill up the form. You will only be able to fill the form in certain regions. For instance, I’m in India and wasn’t able to access the page. However, users in Europe have been able to use the link to attempt to prevent Meta from using their details to train AI models. You’ll have to follow the same process outlined above to proceed.
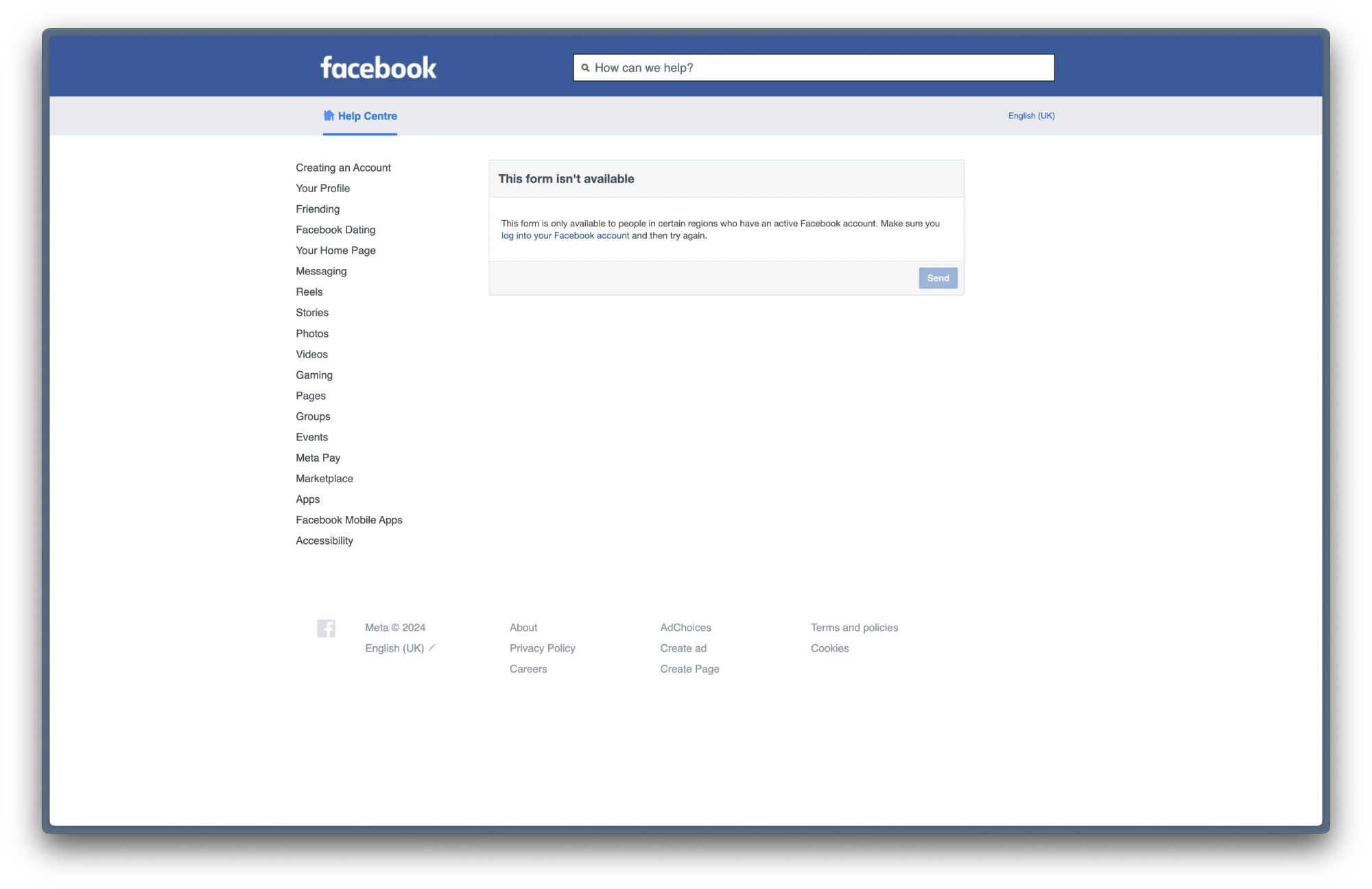
If you can’t access the page, Facebook does have an option for users to request the company to remove any “personal information,” however, this isn’t the same as stopping Facebook from using your data to train AI. You’ll have to submit proof of Meta’s AI using your personal information.
Is there a way to stop Meta scrapping your data in the US?
While Meta isn’t providing users in the US a way to opt-out from its AI training, users can set their accounts to ‘Private.’ as highlighted by the New York Times. Meta only trains its AI based on public activities. Of course, this has its own drawbacks as your engagement will likely plummet.
How Meta uses user data for training AI
Meta is integrating generative AI into its suite of products and services, aiming to enhance user experiences and foster creativity. Generative AI at Meta encompasses a range of features, including Meta AI and AI Creative Tools, designed to assist users in various tasks from organizing personal plans to creating unique content. By making AI models accessible through an open platform, Meta supports a broad community of researchers and developers. These AI models are trained on vast datasets, including publicly available, licensed, and user-shared information from Meta’s platforms, excluding private messages.
Generative AI models work by analyzing massive amounts of data, identifying relationships between different content types, and generating new content based on user inputs. For instance, large language models (LLMs) are trained on extensive text data to perform tasks such as sentence completion and translation, while image generation models learn to create images from text descriptions. Meta employs data from various sources to train these models, including public internet data and licensed information. Although personal information from these sources may be included in training datasets, it is not directly linked to Meta accounts.
Meta claims it prioritizes privacy and ethical considerations in its AI development. The company has established a robust internal Privacy Review process to mitigate potential privacy risks and uphold its core values of privacy, security, fairness, inclusivity, robustness, safety, transparency, and accountability. Meta’s commitment to responsible AI development includes ongoing efforts to ensure equitable access to information and services, adhering to legal standards, and maintaining transparency about data usage. Users have rights regarding their information, and Meta provides resources for submitting related requests. All this seems great on paper, however, after seeing how difficult Meta makes it for users to opt out from the process, I believe the company still has a long way to go.
The need for clearer policies and user controls
As AI capabilities continue advancing rapidly, major tech companies like Meta will likely face increasing scrutiny over their data collection and usage practices related to AI training. Clear and ethical policies that prioritize user privacy, consent, and control will be essential going forward.
At the very least, Meta should streamline the opt-out process by sending an explicit notification about AI training, adding a prominent opt-out button, removing unnecessary steps like confirmation codes, and guaranteeing that all properly submitted objections will be honored. Users’ data is incredibly valuable for AI training, but that doesn’t give companies free rein to use it without consent.
If you value your privacy and want to prevent your personal data from being used to train Meta’s AI systems, be prepared to jump through several intentional hoops for now. It’s the same case for Meta’s AI-powered search that’s now being forced upon Facebook and Instagram users. Luckily, I did find some workarounds to get rid of it. That said, users can keep pushing for simpler, more transparent data policies that respect users’ fundamental rights over their information. There’s even a petition on Change.org to force Meta to provide a clear opt-out option. As AI grows more powerful and prevalent, ensuring consent will only become more crucial.
TechIssuesToday primarily focuses on publishing 'breaking' or 'exclusive' tech news. This means, we are usually the first news website on the whole Internet to highlight the topics we cover daily. So far, our stories have been picked up by many mainstream technology publications like The Verge, Macrumors, Forbes, etc. To know more, head here.













Himanshu Arora
295 Posts
I have been writing tech-focused articles since 2010. In my around 15 years of experience so far, I have written for many leading publications, including Computerworld, GSMArena, TechSpot, HowtoForge, LinuxJournal, and MakeTechEasier to name a few. I also co-founded PiunikaWeb, which went on to become a huge success within 5 years of its inception. Here at TechIssuesToday, I aim to offer you helpful information in a way that you won't find anywhere else easily.

